論文除了內文闡述研究目的、過程與方法,圖表的功能也不容小覷,幾張精確又漂亮的圖表可強調研究結果加快評審審閱,更可能成為論文被accepted的關鍵之一。
今天要介紹的是X-Y散布圖(Scatter plot),將X-Y兩個維度的資料於圖面上點出每個相對應的點。散布圖觀察的主要重點是資料的分佈特性,因此通常適用於連續型數值資料。
以R內建資料集women為例,分別有15筆身高與體重資料
https://stat.ethz.ch/R-manual/R-devel/library/datasets/html/women.html
height
|
weight
|
|
1
|
58
|
115
|
2
|
59
|
117
|
3
|
60
|
120
|
4
|
61
|
123
|
5
|
62
|
126
|
6
|
63
|
129
|
7
|
64
|
132
|
8
|
65
|
135
|
9
|
66
|
139
|
10
|
67
|
142
|
11
|
68
|
146
|
12
|
69
|
150
|
13
|
70
|
154
|
14
|
71
|
159
|
15
|
72
|
164
|
以R繪製散點圖如下

圖型僅有刻度與資料點,所提供的資訊量十分不足,無法單純就圖面知道刻度代表意義,即哪個軸是身高、哪個軸是體重。所以除了刻度之外,應要再加上每個軸的意義與單位

再加上標題跟圖例(Legend)就更完美了,當資料點有多種類別時特別需要使用圖例標示,讓讀者可看圖片就知道不同樣式資料點所代表的類別。
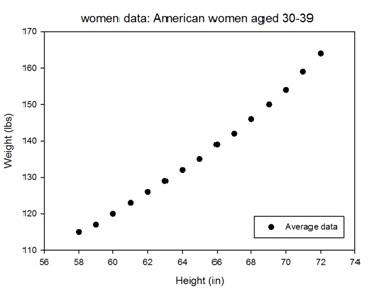
除了上述所說的圖面元素之外,筆者個人習慣會將圖的上邊與右邊的邊線拿掉(box off),如果有分析結果也會直接繪製於圖面上,並且檢查一下刻度是否需要調整。通常當資料點與邊線重疊時(如下圖),筆者就會調整一下刻度範圍,通常將刻度範圍加長即可把資料點移至邊框內。

最後成果如下圖,可以從圖面上知道該圖為年齡30至39間的美國女性身高f(in)與體重X(lbs)平均資料,且就圖面回歸線可知身高越高時,體重會相對的越重,其回歸公式為f= -87.52+3.45*X。

沒有留言:
張貼留言